Debugging Concept Bottleneck Models through Removal and Retraining
Eric Enouen, Sainyam Galhotra
Cornell University

Abstract
Concept Bottleneck Models (CBMs) use a set of human-interpretable concepts to predict the final task label, enabling domain experts to not only validate the CBM’s predictions, but also intervene on incorrect concepts at test time. However, these interventions fail to address systemic misalignment between the CBM and the expert’s reasoning, such as when the model learns shortcuts from biased data. To address this, we present a general interpretable debugging framework for CBMs that follows a two-step process of Removal and Retraining.
In the Removal step, experts use concept explanations to identify and remove any undesired concepts. In the Retraining step, we introduce CBDebug, a novel method that leverages the interpretability of CBMs as a bridge for converting concept-level user feedback into sample-level auxiliary labels. These labels are then used to apply supervised bias mitigation and targeted augmentation, reducing the model’s reliance on undesired concepts.
Concept Bottleneck Debugging Framework
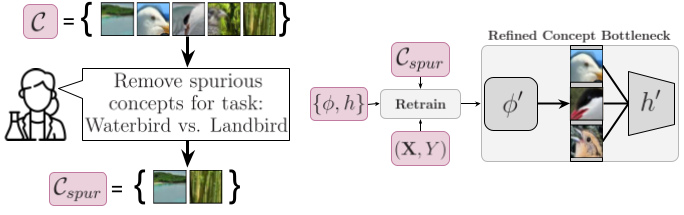
Our debugging framework incorporates a domain expert’s knowledge into a concept bottleneck.
Removal: The user inspects concept explanations and selects undesired concepts to remove, such as background concepts in bird classification.
Retraining: The concept extractor and inference layer are retrained based on this feedback, updating the CBM to remove dependence on undesired concepts while maintaining reliance on task-relevant concepts. We introduce CBDebug to effectively perform this retraining step.
CBDebug
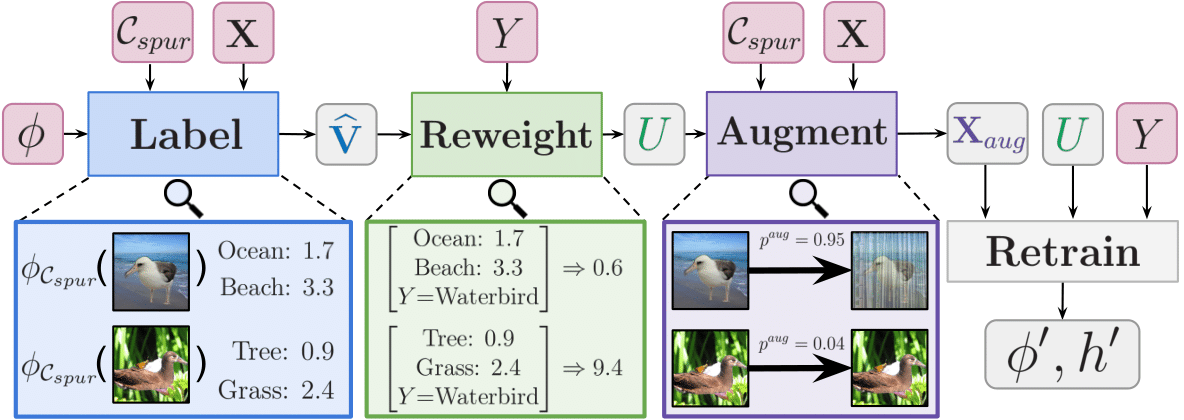
Overview of CBDebug (Concept Bottleneck Debugger), which consists of three main steps. First, the encoder $\phi$ computes the concept activations for undesired concepts in $C_{spur}$ to generate the approximated auxiliary label $\hat{\mathbf{V}}$. Second, permutation weighting utilizes $\hat{\mathbf{V}}$ and the class label $\mathbf{Y}$ to compute the odds of the sample being drawn from the unconfounded distribution, generating weights $\mathbf{U}$. Third, augmentation is performed on $\mathbf{X}$ based on the undesired concepts $C_{spur}$ and weights $\mathbf{U}$ to generate $X_{aug}$. Finally, we retrain ${\phi, h}$ on $(X_{aug}, \mathbf{Y})$ weighted by $\mathbf{U}$ and return ${\phi’, h’}$.
Experiments
We test our approach across PIP-Net and Post-hoc CBM, two popular CBM architectures, and benchmarks with known spurious correlations. We first explore real user feedback, showing that CBDebug greatly improves worst-group accuracy compared to baseline approaches.
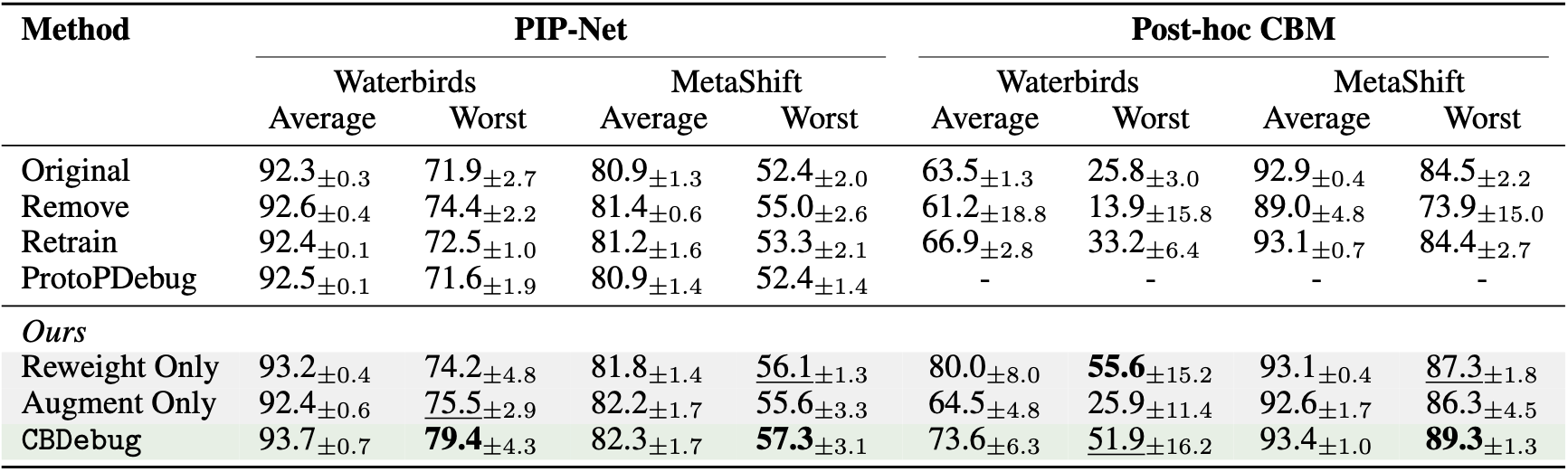
We also show results on Post-hoc CBM with automated feedback from a language model, and achieve similarly robust results.
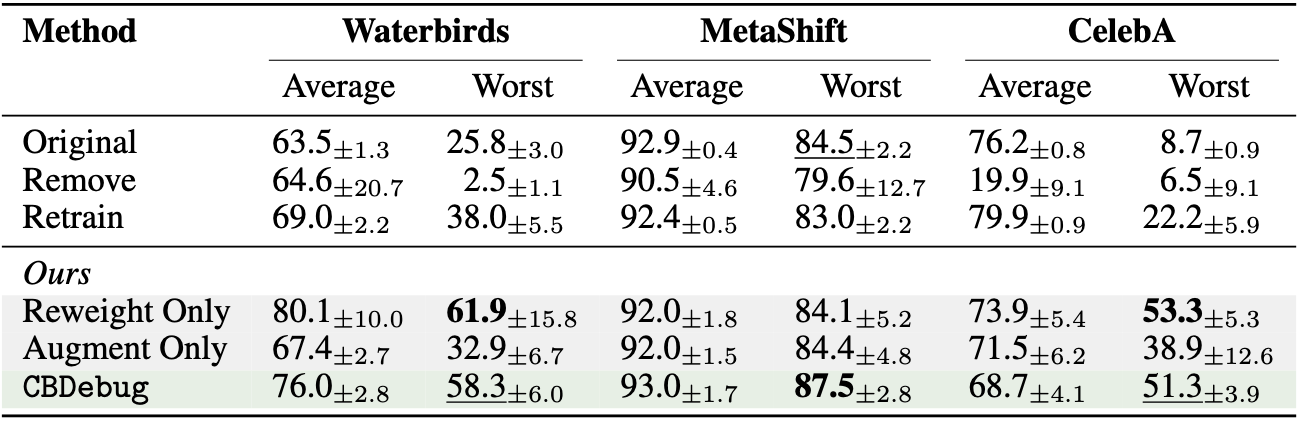
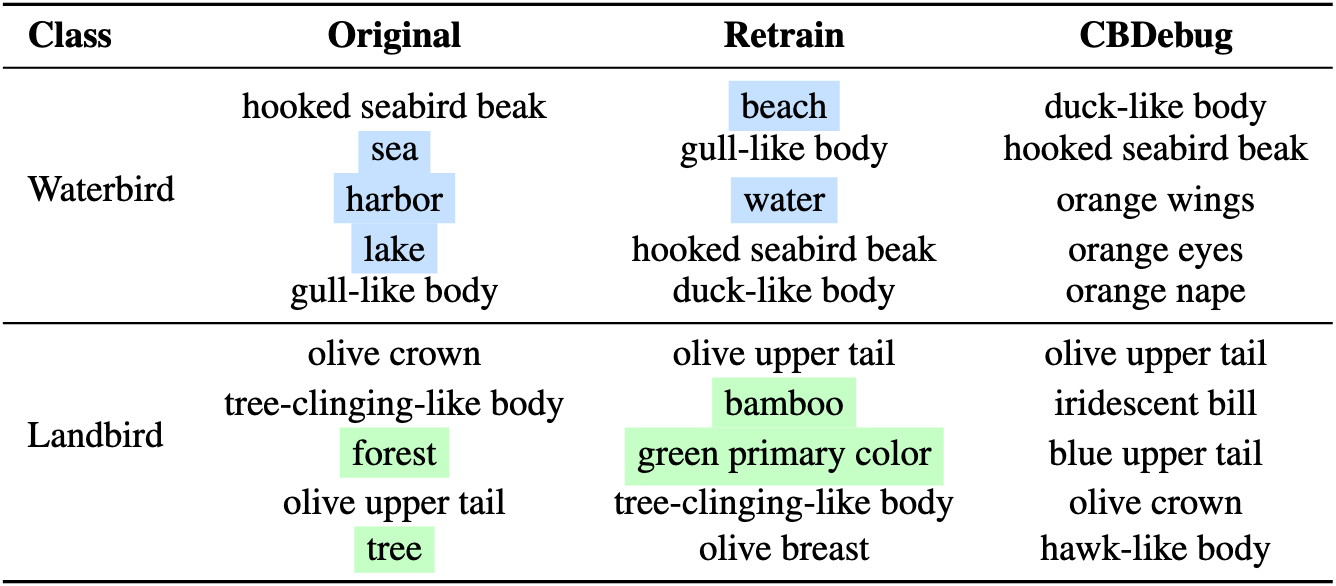
We also show qualitative results comparing CBDebug to baseline Retraining, showing we can more effectively remove reliance on undesired concepts.
Conclusion
- We present an interpretable debugging framework for CBMs, extending prior frameworks to a more general architecture and enabling domain experts to globally edit model reasoning.
- We introduce
CBDebug, a retraining approach that first approximates sample-level auxiliary labels from concept-level feedback, then reweights and augments the dataset to reduce reliance on undesired concepts and better align the model with expert reasoning. - We validate our framework across multiple CBMs (PIP-Net, Post-hoc CBM) and datasets with known spurious correlations.
CBDebugmost effectively leverages user feedback on spurious concepts, outperforming prior work on ProtoPNets and improving worst-group accuracy by up to 26% over the original model, with strong results even when feedback is automated with an LLM.
Cite this Work
@inproceedings{enouen26debug,
title={Debugging Concept Bottleneck Models through Removal and Retraining},
author={Enouen, Eric and Galhotra, Sainyam},
booktitle={ICLR},
year={2026},
}