Bau Lab May Mech Interp Puzzle
In this post I analyze the puzzle from puzzles.baulab.info. The task is to reverse-engineer a 9,600 parameter attention-only transformer trained to count unique tokens. See this Colab notebook for the corresponding code.
Task
Given a sequence of 10 tokens drawn from a vocabulary of 10 symbols, predict the number of distinct symbols. The released model hits 100% accuracy on every count from 1 through 10 on a held-out test set. Reverse-engineer the algorithm it learned.
| Input symbols | 10 (rendered as a – j) |
| Sequence length | 10 input tokens |
| Layers | 2 |
| Heads per layer | 4 |
d_model |
32 |
| Parameters | 9,600 |
| Vocab | 22 tokens (10 input symbols + BOS + ANS + 10 count tokens #1–#10) |
| Positional embeddings | none |
| Causal mask | yes |
Attention-only: no MLPs, no LayerNorm, no positional embeddings.
token_embedding
→ attention layer 1 (4 heads, causal mask) + residual
→ attention layer 2 (4 heads, causal mask) + residual
→ linear unembed → logits
Submission
I will claim in this post that the model partitions the 10-symbol vocabulary into four main groups, each handled by a dedicated mechanism.
| Token group | Handled by | Mechanism Summary |
|---|---|---|
b |
L1 head 0 | Self-attends in L0 → distinctive residual → detected directly |
f |
L1 head 1 | Mostly self-attends in L0 → invisible to anchor circuit → detected directly |
a, h, d, g |
L1 head 2 | L0 heads write anchor OVs into subsequent positions → fingerprint read at last position |
c, e, i, j |
L1 head 3 | L0 heads write ceij tokens to ANS → destructive interference with query → BOS attenuation |
Below is some evidence that the algorithm is split into these four groups, and an explanation of each group’s mechanism in detail.
The Four-Way Partition
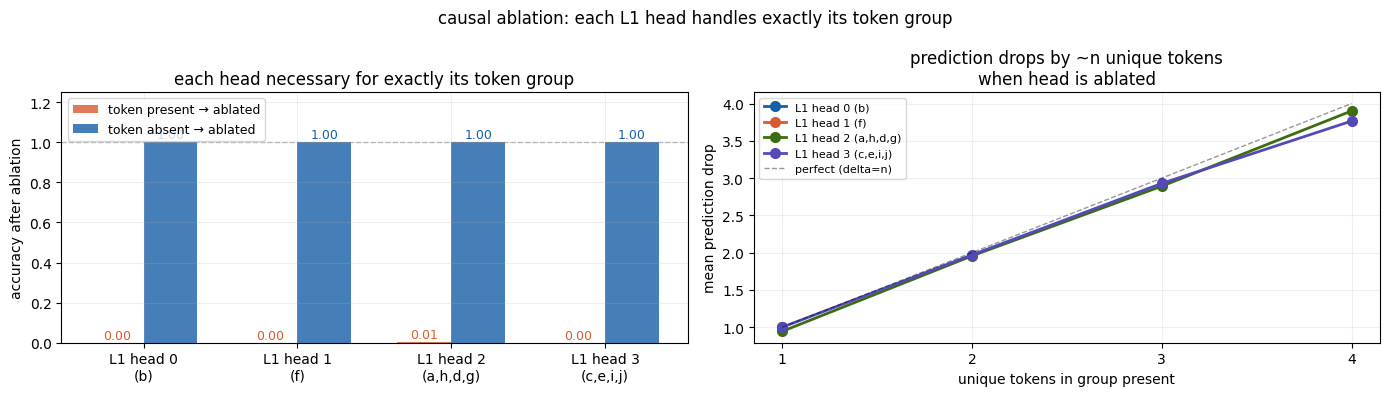
The first piece of evidence is that each layer 1 head is causally necessary for its exact token group. I test this by taking subsets of the input space containing tokens belonging to different groups. Mean ablation of the head drops the count accuracy to 0% when its corresponding tokens are present, but leaves accuracy at 100% when they are absent. Interestingly, the prediction drops by approximately the number of unique tokens in that group, highlighting the additive nature of the counting procedure in layer 1.
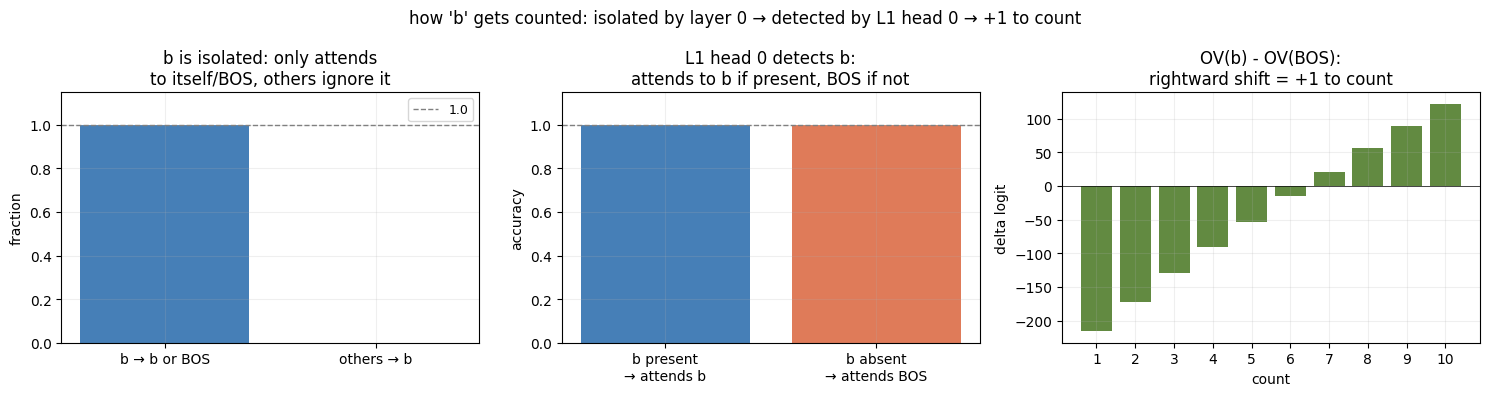
Mechanism 1: Counting b
For this mechanism I claim that b has strongly negative key scores in all four layer 0 heads, causing it to always self-attend rather than accumulate information from other tokens. This gives b a unique residual after layer 0. Layer 1 head 0 then attends directly to b if present (else falls back to BOS), and the difference in value outputs between these two cases produces a clean +1 rightward shift in the count logits.
Key results:
battends only to itself or BOS in Layer 0 (1.000), other tokens never attend tob(0.000)- L1 head 0 attends to
bif present, else BOS (1.000 both ways) - OV(
b) − OV(BOS) is consistently rightward, encoding +1 to the count
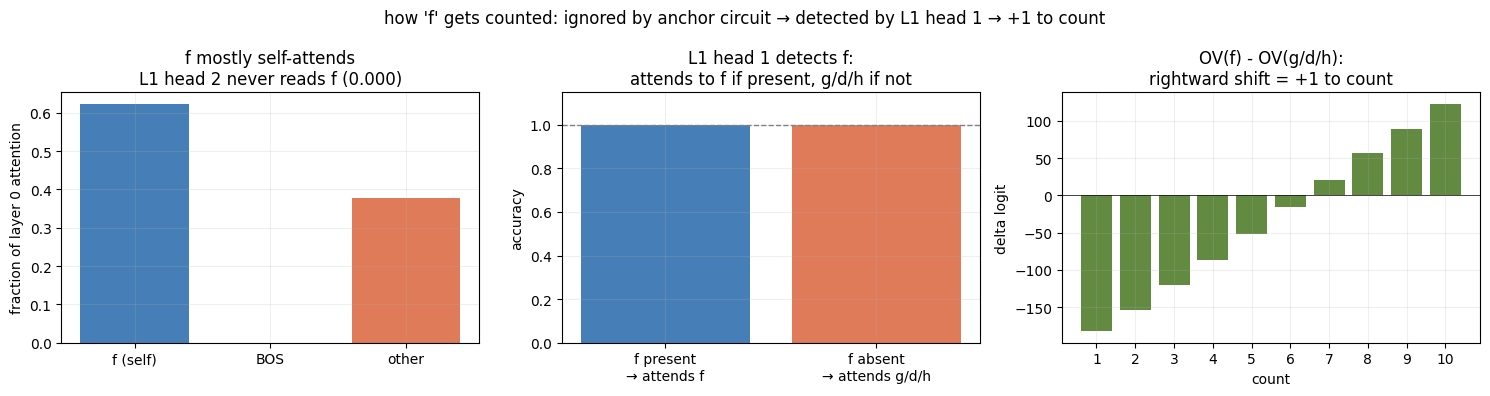
Mechanism 2: Counting f
For this mechanism I claim that f mostly self-attends in Layer 0 (62% self-attention) but unlike b it also reads some anchor content. Crucially however, f has strongly negative key scores in layer 1 head 2, so is still invisible to the anchor counting circuit (0.000 attention from head 2). Instead, layer 1 head 1 detects f directly: it attends to f if present, else falls back to {g,d,h}, and the difference in value outputs again encodes +1 to the count.
Key results:
fmostly self-attends in Layer 0 (62%)- L1 head 2 never attends to
f(0.000).fis invisible to the anchor circuit - L1 head 1 attends to
fif present, else g/d/h. - OV(
f) − OV(g/d/h) projects rightward, encoding exactly +1
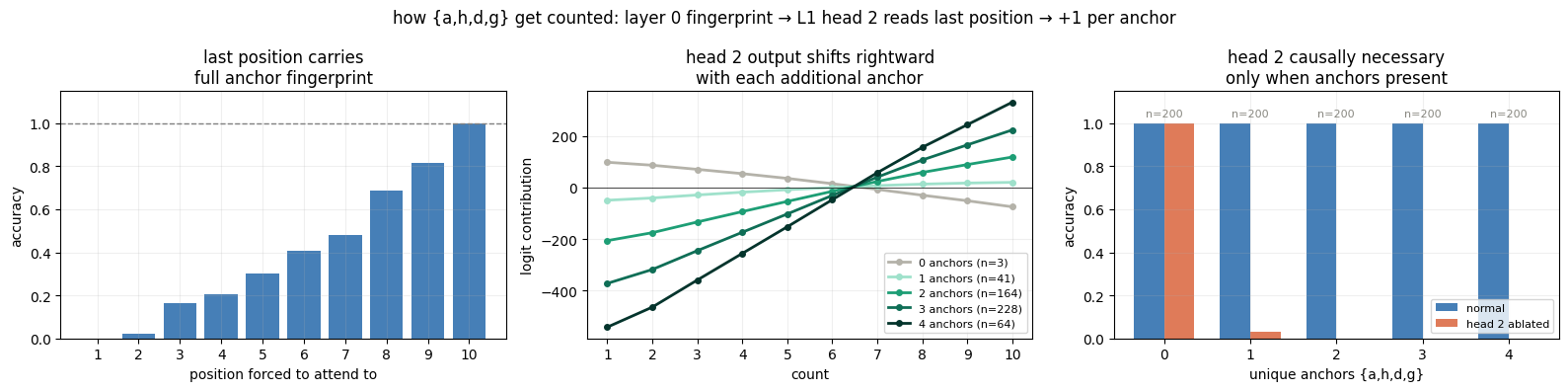
Mechanism 3: Counting a, h, d, g
Each layer 0 head is dedicated to one anchor token (head 0→a, head 1→h, head 2→d, head 3→g). When an anchor is present, every subsequent non-b/f/ANS token attends to it with probability 1.000, causing the anchor’s OV vector to be written into all subsequent residuals. This creates an accumulated fingerprint encoding which anchors appeared. Layer 1 head 2 is biased toward later positions (which have richer fingerprints via higher key scores), and its value circuit produces a rightward logit shift proportional to how many unique anchors were present.
Key results:
- Every non-b/f token after an anchor attends to it: 1.000 for all four heads
- Forcing L1 head 2 to attend to last non-b/f position gives 1.000 accuracy; first position gives 0.002. The last position always contains the full fingerprint
- Head 2 logit contribution scales with anchor count (0→4 anchors produces monotonically increasing rightward shift)
Mechanism 4: Counting c, e, i, j
Since mechanism 3 is using each layer 0 head for each anchor token, I claim that this mechanism learns to write to the ANS token instead to change the query in layer 1. Each layer 0 head writes one designated secondary token to the ANS position (head 0→i, head 1→j, head 2→c, head 3→e). These OV vectors accumulate in the ANS residual, which becomes the query for all layer 1 heads. Each ceij token’s OV contribution points approximately opposite to the baseline ANS query (~0.98 cosine similarity with −q_base), causing destructive interference that progressively cancels the query magnitude. This reduces ANS’s attention to BOS in Layer 1 head 3. Since BOS provides a strong low-count baseline signal, attenuating it raises the predicted count by approximately +1 per unique ceij token present.
Key results:
- Each L0 head writes one ceij token to ANS: head 0→
i, head 1→j, head 2→c, head 3→e. Forcing this assignment gives 1.000 accuracy - Each ceij token’s query shift is ~0.98 anti-parallel to the baseline query (destructive interference)
- q·k_BOS drops monotonically with ceij count: 19.2 → 11.6 → 8.9 → 6.3 → 3.6
- BOS logit contribution shrinks with each additional ceij token, reducing the low-count bias

Final Summary
This model solves unique token counting through a clean four-way partition of the vocabulary, with each subset handled by a dedicated layer 1 head using information prepared by Layer 0.
The key insight is that Layer 0 serves a different role for each group:
- b, f: isolated from the rest of the circuit by self-attention, leaving distinctive residuals for direct detection
- a, h, d, g: each head propagates its anchor’s presence forward through the sequence via OV writes, accumulating a fingerprint at later positions
- c, e, i, j: each head writes its designated secondary token into the ANS residual, which then alters the query for layer 1
Layer 1 then reads off these signals independently:
- Head 0, 1: binary detectors for b and f, contributing exactly +1 when present
- Head 2: reads the anchor fingerprint from the last non-b/f position, contributing +1 per unique anchor
- Head 3: its baseline query points toward BOS (low-count bias); each ceij token destructively interferes with this query, attenuating BOS attention and contributing +1 per unique ceij token
The four contributions combine additively to produce the correct total count, achieving 100% accuracy across all counts 1–10. The solution exhibits perfect coverage with zero redundancy.